
Multi-Modal AI
Bridging the Gap Between Vision, Language & Intelligence
In a world overflowing with both images and information, true intelligence comes from understanding what we see and what we read — together.
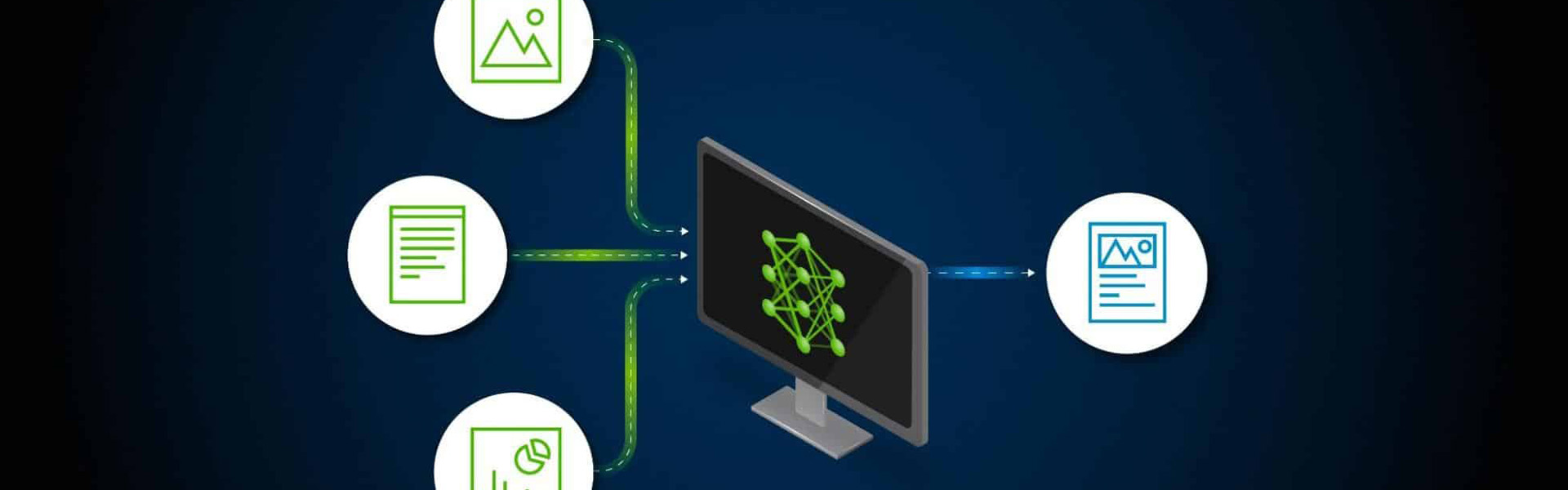
At Dreamline Technologies, our Multi-Modal AI (Vision + Text) solutions integrate computer vision and natural language processing (NLP) to help organizations analyze, interpret, and act on complex data from multiple sources — documents, images, videos, and text.
From automated document parsing to product tagging and visual inspection, we help businesses build AI systems that see, read, and understand like humans — but faster, more accurately, and at scale.
What We Deliver
Capability
Document Intelligence & Parsing
Visual Recognition & Tagging
Image-to-Text Understanding
Knowledge Extraction from Visuals
Anomaly Detection & Quality Control
Description
Extract data from invoices, resumes, contracts, and identity documents using OCR + LLMs.
Auto-tag and classify product catalogs, real estate photos, or medical images for instant organization.
Generate rich captions, summaries, or metadata from visual content using AI-powered perception models.
Combine text and image insights to build searchable knowledge bases (for legal, healthcare, or logistics).
Use computer vision to identify defects, compliance issues, or process anomalies in real time.
Why Multi-Modal AI Matters Now

Unstructured Data Explosion
80% of enterprise data is unstructured — trapped in PDFs, images, and chat logs.
Multi-modal AI unlocks this hidden value, making it searchable and actionable.

Beyond Text-Only AI
Language models alone can’t interpret visual context.
Multi-modal systems combine vision + language to deliver a full-spectrum understanding of content.

Faster Decision-Making
Businesses no longer need teams manually reading reports or scanning photos — AI can analyze thousands per minute.

Cross-Industry Impact
Whether in healthcare diagnostics, insurance claims, logistics, or e-commerce — multi-modal intelligence powers next-gen automation.
Real-World Use Cases
Industry
Application
Outcome
E-commerce
Auto-tagging & AI search from product photos
10× faster catalog management & improved discoverability
Finance
OCR + NLP to extract data from KYC & loan documents
Reduced processing time from 3 days to 3 hours
Healthcare
Scan reports & X-rays to summarize findings for doctors
Faster diagnosis support with AI-driven summaries
Legal & Insurance
Analyze scanned documents and handwritten notes
Automated compliance & claim processing
Manufacturing
Visual inspection for quality control
95% defect detection accuracy
Logistics
Read and interpret shipping labels & bills
Error-free, real-time inventory tracking
Before vs After Multi-Modal AI Transformation
Aspect
Before AI
After Multi-Modal AI
Document Processing
Manual data entry, time-consuming
Fully automated extraction & validation
Product Categorization
Human tagging & errors
AI auto-tags with 99% accuracy
Compliance Verification
Random manual checks
AI scans every document/image instantly
Aspect
Before AI
After Multi-Modal AI
Customer Experience
Limited search and retrieval
AI visual + text search for smarter discovery
Decision Support
Based on incomplete data
Unified insights combining image + text data

Technologies & Frameworks We Use

Computer Vision: OpenCV, TensorFlow Vision, PyTorch, Detectron2, YOLO

OCR & Document AI: Google Document AI, Azure Form Recognizer, AWS Textract, Tesseract

NLP & LLMs: OpenAI GPT, Claude, Gemini, LangChain, Hugging Face Transformers

Integration Tools: FastAPI, Streamlit, Power Automate, Zapier, Make
Data Storage & Pipelines: Weaviate, Pinecone, PostgreSQL, AWS S3, Azure Blob
Ideal for Organizations That:
- Manage large volumes of visual and document-based data
- Need automated classification, extraction, and compliance checks
- Want to build smarter AI search and recommendation systems
- Aim to reduce manual work and improve operational accuracy
Why Choose Dreamline Technologies
- Custom-Built Multi-Modal Models – tailored to your data, not generic APIs
- Cross-Platform Integration – seamlessly embedded in your CRM, ERP, or cloud stack
- Scalable Architecture – ready for millions of files and high-frequency workloads
- Ethical AI & Compliance – privacy-first model design, compliant with GDPR & data laws
Single-Modal AI vs Multi-Modal AI — The Next Evolution in Intelligence
Aspect
Single-Modal AI
Multi-Modal AI (Vision + Text)
Input Type
Works with only one data type — text, image, or audio
Processes multiple inputs (e.g., image + text, video + metadata) simultaneously
Understanding Level
Limited context — interprets data within one domain
Deep contextual understanding — combines visual + linguistic meaning
Example Use Case
Chatbot answering based only on text
AI assistant analyzing documents + reading attached images to respond accurately
Data Integration
Separate pipelines for each data source
Unified pipeline merging image, text, and metadata into one intelligent layer
Accuracy & Insight
Prone to misinterpretation due to missing context
High accuracy — visual and text signals reinforce each other
Automation Scope
Restricted to structured or textual data
Automates unstructured data workflows (documents, photos, scans, videos)
Scalability
Limited insights when data grows in complexity
Scales easily across industries handling multi-format enterprise data
Typical Output
Text-only results (answers, summaries)
Contextual results — captions, insights, recommendations, or analytics
Technology Example
ChatGPT text model, Speech-to-Text, OCR-only
GPT-4 Vision, Gemini, Claude 3 Opus, or LangChain Multi-Modal pipelines
Ideal Use Case
FAQ chatbots, text summarization, content generation
Document intelligence, visual QA, product discovery, smart customer support
Why Businesses Are Upgrading
- 90% of new enterprise AI models launched since 2024 are multi-modal (Source: Gartner 2025).
- Companies report 40–60% reduction in data processing time when switching from text-only AI to multi-modal AI.
- Multi-modal systems improve decision accuracy by up to 30% because they analyze context across formats.